Giới Thiệu Machine Learning - Phương Phap SVM
Giới thiệu
SVM là mô hình được sử dụng trong nhiều ngành, là một mô hình máy học giám sát được dùng để phân tích, phân lớp dữ liệu. Có thể những điều ở đây khá trừ tượng. Trong bài viết này, tôi sẽ giới thiệu một cách tổng quan về mô hình SVM và ví dụ về SVM trong OPenCV.
SVM là gì?
SVM (Support Vector Machine) là một khái niệm trong thống kê và khoa học máy tính cho một tập hợp các phương pháp học có giám sát liên quan đến nhau để phân loại và phân tích hồi quy.
SVM là một thuật toán phân loại nhị phân, SVM nhận dữ liệu vào và phân loại chúng vào hai lớp khác nhau. Với một bộ các ví dụ luyện tập thuộc hai thể loại cho trước, thuật toán luyện tập SVM xây dựng một mô hình SVM để phân loại các ví dụ khác vào hai thể loại đó.
Ví dụ về SVM tuyến tính
Tôi có một khôn gian có nhiều điểm và các kí hiệu như sau:

Phân tích
- yi: Đây là các lớp (Bản lề) chứa các điểm dữ liệu xi. Ở ví dụ này mang giá trị 1 và -1.
- xi: Là một vector thực nhiều chiều (p chiều).
- Nhiệm vụ là cần phải tìm một siêu phẳng (Optimal hyperplane) có lề lớn nhất chia tách các điểm dữ liệu có ban đầu để huấn luyện và các điểm sau này. Mỗi siêu phẳng (Optimal hyperplane) đều có thể được viết dưới dạng một tập các điểm thỏa mãn:
- w.x-b = 0
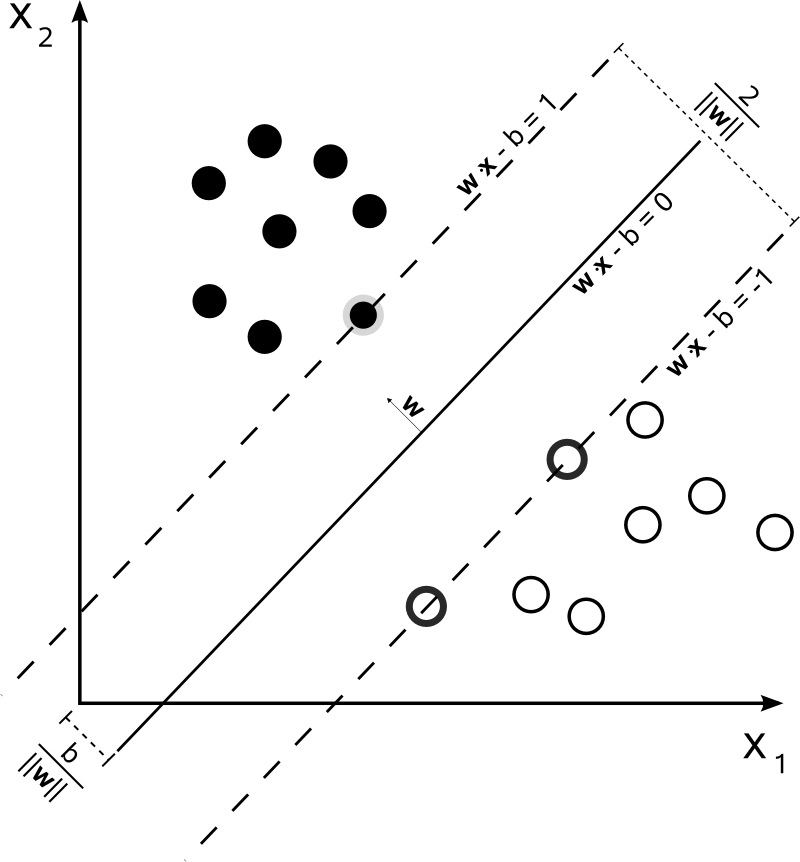
- w: Là một vectơ pháp tuyến của siêu phẳng (Optimal hyperplane).
- Tham số b/||w|| xác định khoảng cách giữa gốc tọa độ và siêu phẳng theo hướng vectơ pháp tuyến w.
- Như bạn có thể thấy ở hình s1. Tôi giả sử có tới 3 siêu phẳng (Optimal hyperplane) là H1 (Xanh dương), H2 (Đỏ), H3 (Xanh lá). H3 sẽ bị loại đầu tiên vì không thể phân loại các điểm huấn luyện cho trước. H1bị loại vì khoảng cách từ các điểm Support Vector đến siêu phẳng (Optimal hyperplane) chưa phải là cực đại. H2 là siêu phẳng cần tìm. Lúc này các siêu phẳng đó được xác định:
- w.x - b = 1
và
- w.x - b = -1
- Các điểm dữ liệu cho trước nằm trên các siêu phẳng song song được gọi là Support Vector.
Tổng quan
- SVM là mô hình xây dựng một siêu phẳng hoặc một tập hợp các siêu phẳng trong một không gian nhiều chiều hoặc vô hạn chiều, có thể được sử dụng cho phân loại, hồi quy, hoặc các nhiệm vụ khác. Để phân loại tốt nhất thì phải xác định siêu phẳng (Optimal hyperplane) nằm ở càng xa các điểm dữ liệu của tất cả các lớp (Hàm lề) càng tốt, vì nói chung lề càng lớn thì sai số tổng quát hóa của thuật toán phân loại càng bé.
- Muốn các điểm dữ liệu có thể được chia tách một cách tuyến tính, thì bạn phải cần chọn hai siêu phẳng của lề sao cho không có điểm nào ở giữa chúng và khoảng cách giữa chúng là tối đa.
- Trong nhiều trường hợp, không thể phân chia các lớp dữ liệu một cách tuyến tính trong một không gian ban đầu được dùng để mô tả một vấn đề. Vì vậy, nhiều khi cần phải ánh xạ các điểm dữ liệu trong không gian ban đầu vào một không gian mới nhiều chiều hơn, để việc phân tách chúng trở nên dễ dàng hơn trong không gian mới. Chú ý: Trong bài viết này, tôi chỉ giới thiệu tổng quan về mô hình SVM và SVM trong OpenCV được sử dụng như thế nào? Vì vậy, tôi không đi sâu vào nội dung này. Bạn có thể tham khảo tại mục Tham khảo
Với các điểm tổng quan ở trên thì nhiệm vụ chính là phân loại thống kê.
- Thuật toán được cho trước một số điểm dữ liệu cùng với nhãn của chúng thuộc các lớp cho trước (Huấn luyện).
- Mục tiêu của thuật toán là xác định xem một điểm dữ liệu mới sẽ được thuộc về lớp nào (Phân loại).
SVM trong OpenCV
Source code
- #include <opencv2/core.hpp>
- #include <opencv2/imgproc.hpp>
- #include "opencv2/imgcodecs.hpp"
- #include <opencv2/highgui.hpp>
- #include <opencv2/ml.hpp>
- using namespace cv;
- using namespace cv::ml;
- int main(int, char**)
- {
- int width = 512, height = 512;
- Mat image = Mat::zeros(height, width, CV_8UC3);
- int labels[4] = { 1, 1, 1, -1 };
- Mat labelsMat(4, 1, CV_32SC1, labels);
- float trainingData[4][2] = { { 501, 10 }, { 255, 10 }, { 501, 255 }, { 10, 501 } };
- Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
- Ptr<ml::SVM> svm = ml::SVM::create();
- svm->setType(ml::SVM::C_SVC);
- svm->setKernel(ml::SVM::LINEAR);
- svm->setTermCriteria(cv::TermCriteria(CV_TERMCRIT_ITER, 100, 1e-6));
- svm->train(trainingDataMat, ml::ROW_SAMPLE, labelsMat);
- Vec3b green(0, 255, 0), blue(255, 0, 0);
- for (int i = 0; i < image.rows; ++i)
- for (int j = 0; j < image.cols; ++j) {
- Mat sampleMat = (Mat_<float>(1, 2) << j, i);
- float response = svm->predict(sampleMat);
- if (response == 1)
- image.at<Vec3b>(i, j) = green;
- else if (response == -1)
- image.at<Vec3b>(i, j) = blue;
- }
- int thickness = -1;
- int lineType = 8;
- circle(image, Point(501, 10), 5, Scalar(0, 0, 0), thickness, lineType); // black
- circle(image, Point(255, 10), 5, Scalar(255, 255, 255), thickness, lineType); // white
- circle(image, Point(501, 255), 5, Scalar(0, 0, 255), thickness, lineType); // red
- circle(image, Point(10, 501), 5, Scalar(0, 255, 0), thickness, lineType); // green
- imshow("SVM Simple Example", image);
- waitKey(0);
- }
Phân tích
Thiết lập dữ liệu huấn luyện
- float labels[4] = {1.0, -1.0, -1.0, -1.0};
- float trainingData[4][2] = {{501, 10}, {255, 10}, {501, 255}, {10, 501}};
Dữ liệu được huấn luyện được tạo thành bởi một tập điểm có giá trị 2D. Ở đoạn code trên, tôi có:
- 2 lớp: Lớp thứ nhất mang giá trị -1, và lớp thứ hai mang giá trị 1 (lables).
- 4 điểm dữ liệu (Điểm được dùng để huấn luyện mô hình SVM) cho trước ứng với giá trị của lớp: (501, 10) thuộc lớp thứ hai, và 3 điểm còn lại thuộc lớp thứ nhất.
Chú ý: Số lượng phần tử của ma trận labels bằng với số cột của ma trận của trainingData.
- Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
- Mat labelsMat(4, 1, CV_32FC1, labels);
Chú ý: Hàm CvSVM::train() sử dụng kiểu dữ liệu truyền vào là kiểu Mat.
Thiết lập thông số của SVM
- // Set up SVM's parameters
- Ptr<ml::SVM> svm = ml::SVM::create();
- svm->setType(ml::SVM::C_SVC);
- svm->setKernel(ml::SVM::LINEAR);
- svm->setTermCriteria(cv::TermCriteria(CV_TERMCRIT_ITER, 100, 1e-6));
Phân tích
- Type SVM: Tôi chọn ml::SVM::C_SVC để có thể được sử dụng để phân loại nhiều (n) lớp (n>2). Tham số này được xác định trong thuộc tính ml::SVM::Params.svmType. Lưu ý: Chức năng quan trọng của loại SVM CvSVM::C_SVC là tách hoàn hảo của các lớp học (Tức là khi dữ liệu đào tạo là không bị phân chia qua các lớp khác).
- Type SVM kernel: Là một tham số này được xác định trong thuộc tính ml::SVM.KernelType.
- Termination criteria of the algorithm: Là một tham số này được định nghĩa trong một cấu trúc cv::TermCriteria.
Chú ý: Như ở phần Đối tượng hướng đến trong bài viết. Tôi sử dụng OpenCV 3.0. Với các phiên bản khác của OpenCV, để thiết lập thông số cho SVM sẽ có cách hiện thực khác.
Huấn luyện SVM
Để xây dựng mô hình huấn luyện SVM, tôi sử dụng phương thức CvSVM::train().
- CvSVM SVM;
- SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
Như vậy tôi đã huấn luyện xong cho mô hình SVM của ví dụ ở trên.
Phân loại lớp (Bản lề)
Phương pháp CvSVM::predict() được sử dụng để phân loại một mẫu đầu vào bằng cách sử dụng một SVM được huấn luyện.
- Vec3b green(0,255,0), blue (255,0,0);
- for (int i = 0; i < image.rows; ++i) {
- for (int j = 0; j < image.cols; ++j)
- {
- Mat sampleMat = (Mat_<float>(1,2) << i,j);
- float response = SVM.predict(sampleMat);
- if (response == 1)
- image.at<Vec3b>(j, i) = green;
- else if (response == -1)
- image.at<Vec3b>(j, i) = blue;
- }
- }

Như bạn thấy ở trên, đây chính là kết quả của đoạn code trên.
- Với các điểm tròn nhỏ màu đen, trắng, đỏ, xanh lá cây: Đây chính là các điểm dữ liệu cho trước.
- Ranh giới giữa màu xanh lá cây và xanh dương: Đây chính là siêu phẳng (Optimal hyperplane) của mô hình SVM. Bạn có thể thấy rằng, khoảng cách giữa điểm tròn xanh lá cây tới siêu phẳng (Optimal hyperplane) sẽ bằng khoảng cách giữa điểm tròn màu đỏ tớisiêu phẳng (Optimal hyperplane) (Tương tự với điểm tròn màu trắng).
- Dòng 6: Là một cách khởi tạo một ma trận, nó sẽ có giá trị như sau: sampleMat = [i, j]. Ví dụ: Mat M = (Mat_(2,4) << 1, 0, 0, 0, 1, 0, 0, 0;. Kết quả là M = [1, 0, 0, 0, 1, 0, 0, 0])
- Vậy là đoạn code ở trên sẽ phân loại các điểm dữ liệu thuộc vào lớp nào trên mô hình SVM mà tôi đã huấn luyện ở trên.
Support Vector
Trong OpenCV 3.0, để có thể lấy được các điểm Support Vector thì sử dụng phương thức SVM::getSupportVectors(). Kiểu trả về ở đây là một Mat, với số hàng (Rows) chính là số lượng của các điểm Support Vector
Tổng kết
Trong bài viết này, tôi đã giới thiệu sơ qua về mô hình SVM cũng như ví dụ về hoạt động của SVM trong OpenCV. Ứng dụng của SVM trong các lĩnh vực nói chung là rất nhiều. Ở trong xử lý ảnh, SVM cũng tác dụng to lớn nhiều trong các ứng dụng như trong ứng dụng nhận dạng ký tự viết tay, nhận dạng biển số xe,...
Mọi thắc mắc có thể bình luận tại bài viết hoặc liên hệ với Trương Đạt.
Tham khảo
http://docs.opencv.org/
https://en.wikipedia.org/wiki/Support_vector_machine
(Nguon:Stdio)
Ví dụ: Nhận dạng biển số xe sử dụng SVM
Giới Thiệu Machine Learning - Phương Phap SVM
 Reviewed by Jacky
on
tháng 10 26, 2017
Rating:
Reviewed by Jacky
on
tháng 10 26, 2017
Rating:
Reviewed by Jacky
on
tháng 10 26, 2017
Rating:




Không có nhận xét nào: